
Abstract
In an influential paper, Wendy Parker argues that agreement across climate models isn’t a reliable marker of confirmation in the context of cutting-edge climate science. In this paper, I argue that while Parker’s conclusion is generally correct, there is an important class of exceptions. Broadly speaking, agreement is not a reliable marker of confirmation when the hypotheses under consideration are mutually consistent—when, e.g., we’re concerned with overlapping ranges. Since many cutting-edge questions in climate modeling require making distinctions between mutually consistent hypotheses, agreement across models will be generally unreliable in this domain. In cases where we are only concerned with mutually exclusive hypotheses, by contrast, agreement across climate models is plausibly a reliable marker of confirmation.
Similar content being viewed by others

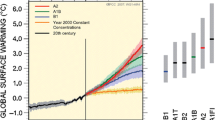
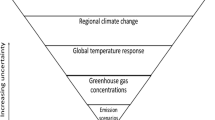
Notes
Lloyd (2015a) makes a similar point on very different grounds.
Why focus on probability-raising here? Because some of the other desiderata for a good hypothesis—such as informativeness or decision-relevance—trade off with posterior probability. For instance: the hypothesis that ECS is in the range 1.0-5.0\(^{\circ }\)C will always be more probable but less informative than the hypothesis that it is in the range 1.5-4.5\(^{\circ }\)C. What we want from our evidence is information about how much more probable—that is, we want it to raise the probability of one hypothesis relative to the other (see §4 for further discussion).
There are a variety of different views in this vicinity, each with their own caveats and alternatives. See, e.g., Carrier and Lenhard (2019), Jebeile and Barberousse (2021), Katzav et al. (2021), Parker and Risbey (2015), Stainforth et al. (2007), and Winsberg (2018). For a contrasting view, see Dethier (2022, 2023a).
This treatment of agreement should be distinguished from those in which agreement (or a related concept like “robustness”) is interpreted as a particular probabilistic condition (see, e.g., Dethier, forthcoming; Schupbach, 2018). Since I’m following Parker closely here, I’m adopting her approach, but in other contexts an alternative understanding of agreement may be preferable.
We can model Parker’s concept of agreement as follows. Let \(s_i\) represent what I’m calling the estimate and what Parker calls the “statement” of the \(i^{\text {th}}\) model. Then two models agree on \(h_1\) iff \(s_1 \vDash h_1\) and \(s_2 \vDash h_1\). Note that the evidence (\(e_i\)) in this situation is not \(s_i\) but the fact that the \(i^{\text {th}}\) model “says” that \(s_i\). After all, within this idealized setting, we can assume that we know what the model says, but we can’t update on the truth of that content because we don’t know whether “what the model says” is true. Agreement is then a reliable marker of confirmation to the extent that agreement (\(s_1 \vDash h_1\) and \(s_2 \vDash h_1\)) makes confirmation (\( Pr(e_1 \& e_2|h_1) > Pr(e_1 \& e_2|h_2)\)) likely.
Of course, if we view the formalism here itself as a model of the testing situation, we might reasonably only draw qualitative conclusions about “real” degree of confirmation. My point here is that formal measures of confirmation track the ratio between the two V terms.
Dethier (forthcoming), Myrvold (1996), and Wheeler (2012) all make this point explicitly using variations on the same formalism adopted here. The point holds in other settings, however, as illustrated by the work of Bovens and Hartmann (2003) and Schupbach (2018).
Of course, putting the question in these terms is potentially misleading in one respect: the ranges for ECS are not put forward ahead of time as hypotheses; instead, they’re inferred—typically using statistics—from the outputs of models and other evidence. My discussion here should be understood as representing the formal support relationships between the evidence and the space of hypotheses that we could draw inferences about on the basis of that evidence and not as capturing anything like the temporal order involved in the practice of drawing these inferences.
Though that doesn’t mean that they’re inaccurate in the same way. On the contrary, there’s a known correlation between error and spread: when the models get a prediction wrong, they tend to get it wrong in a bunch of different ways (see Knutti et al., 2010).
My point here is not that we should add error bars around \(h_1\) in this case, but that the mere presence of idealizations doesn’t undermine the convergence condition except in special cases; see the next paragraph.
As one reviewer stressed, one can imagine extreme scenarios—where, e.g., \(h_1\) specifies ECS to five significant digits—where we should expect some idealization explains the agreement. I agree, but think the explanation for our intuition here is that the prior for the relevant \(h_1\) is extremely low and the observed agreement is extremely surprising whether or not \(h_1\) is true—it’s not that \(\lnot h_1\) offers any better explanation of it that \(h_1\) does. Indeed, our confidence in \(h_1\) in this scenario should increase! Just not enough to overcome the low prior.
The claim here is: where climate scientists haven’t found these interactions, we don’t have sufficient reason to expect them to exist. The restriction is important. In other contexts, we might expect that such interactions are common enough that even experts miss them with a high degree of frequency. I see no reason to postulate that that’s the case here, however.
Reasonably, Parker doesn’t define “significant,” but she does note that it depends on contextual factors (Parker, 2018, 281).
Of course, there’s no guarantee that the models will agree on all of the mutually consistent hypotheses that we’re interested in. In that case, by the reasoning of the last section, there will be some confirmation of the set of hypotheses that the models do agree on. But notice: if the models all fall within the range 1.0-5.0\(^{\circ }\)C, my arguments in the last section strictly only warrant increased confidence that ECS falls within that range relative to the hypothesis that it doesn’t. Plausibly, my arguments could be extended to confirmation relative to a fully excluded range, like 6.0-10.0\(^{\circ }\)C. But they don’t extend to confirmation relative to 1.0-10.0\(^{\circ }\)C. As we’ll see in the next section, these kinds of overlapping hypotheses with what are effectively different “error bars" are one of the major cases that Parker is concerned with. Or, in other words, in the cases at issue, our prior probability is often sufficiently concentrated that at least some results fall within the scope of each of the interesting hypotheses. Where that isn’t true, however, I’m happy to acknowledge that we have confirmation of some subset of the mutually consistent hypotheses.
The use of “consequent” here can be made more appropriate by reframing the discussion in terms of an agreement conditional and a confirmation conditional á la Joyce (1999), but I think that’s unnecessary for communicating the point.
The following discussion is simplified, but a close evaluation of Perrin’s work vindicates the general picture while complicating our understanding of how well Perrin himself succeed at the task (see Smith & Seth, 2020, chapter 6).
Why not? Agreement ignores question of distribution: if we’re asking whether the set of estimates agrees on h, we’re putting aside variation in how much the different estimates support h or where the different estimates fall within the range captured by h. In Bayesian terms, we’re not updating on the total evidence. One way of viewing cases in which agreement is a good heuristic is that they’re cases in which the distribution makes little difference and so updating only on agreement approximates the results that we would get if we updated on the total evidence. As one reviewer stressed to me, at face value this point supports the argument by Lloyd (2015b) and others that we should adopt a different understanding of “robustness.”
Of course, the real question here is “what is the value of ECS?” which is plausibly a question where the answers are mutually exclusive. But the models don’t agree on that question—they deliver a range of different answers—and so the agreement heuristic cannot help us there.
Notably the IPCC doesn’t appeal to model agreement in answering this question; by all appearances, their reasoning is purely statistical.
References
Baumberger, C., Knutti, R., & Hirsch Hadorn, G. (2017). Building confidence in climate model projections: An analysis of inferences from fit. Wiley Interdisciplinary Reviews: Climate Change, 8(3), e454.
Boé, J., Somot, S., Corre, L., & Nabat, P. (2020). Large discrepancies in summer climate change over Europe as projected by global and regional climate models: Causes and consequences. Climate Dynamics, 54, 2981–3002.
Bovens, L., & Hartmann, S. (2003). Bayesian Epistemology. Oxford University Press.
Carrier, M., & Lenhard, J. (2019). Climate models: How to assess their reliability. International Studies in the Philosophy of Science, 32(2), 81–100.
Chandler, J. (2007). Solving the tacking problem with contrast classes. British Journal for the Philosophy of Science, 58(3), 489–502.
Chandler, J. (2013). Contrastive confirmation: Some competing accounts. Syntese, 190(1), 129–138.
Dai, A., Huang, D., Rose, B. E. J., Zhu, J., & Tian, X. (2020). Improved methods for estimating equilibrium climate sensitivity from transient warming simulations. Climate Dynamics, 54(11–12), 4515–4543.
Dethier, C. (forthcoming). The unity of robustness: Why agreement across model reports is just as valuable as agreement among experiments. Erkenntnis
Dethier, C. (2022). When is an ensemble like a sample? ‘Model-Based’ inferences in climate modeling. Synthese, 200(52), 1–20.
Dethier, C. (2023a). Against “Possibilist’’ interpretations of climate models. Philosophy of Science, 90(5), 1417–1426.
Dethier, C. (2023b). Interpreting the probabilistic language in IPCC reports. Ergo, 10(8), 203–225.
Dong, Y., Armour, K. C., Zelinka, M. D., Proistosescu, C., Battisti, D. S., Zhou, C., & Andrews, T. (2020). Intermodel spread in the pattern effect and its contribution to climate sensitivity in CMIP5 and CMIP6 models. Journal of Climate, 33(18), 7755–7775.
Eyring, V., Bock, L., Lauer, A., Righi, M., Schlund, M., Andela, B., Arnone, E., Bellprat, O., Broetz, B., Caron, L.-P., Carvalhais, N., Cionni, I., Cortesi, N., Crezee, B., Davin, E. L., Davini, P., Debeire, K., de Mora, L., Deser, C., . . . Zimmermann, K. (2020). Earth system model evaluation tool (ESMValTool) v2.0 – an extended set of large-scale diagnostics for quasi-operational and comprehensive evaluation of Earth system models in CMIP. Geoscientific Model Development, 13(7), 3383–3438.
Frigg, R., Thompson, E., & Werndl, C. (2015). Philosophy of climate science part II: Modeling climate change. Philosophy Compass, 10(12), 965–977.
Gluck, S. (2023). Robustness of climate models. Philosophy of Science, 90(5), 1407–1416.
Gregory, J. M., Andrews, T., Ceppi, P., Mauritsen, T., & Webb, J. M. (2020). How accurately can the climate sensitivity to CO$_2$ be estimated from historical climate change? Climate Dynamics, 54(1–2), 129–157.
Harris, M., & Frigg, R. (2023). Climate models and robustness analysis – part II: The justificatory challenge. In G. Pellegrino, & M. Di Paola (Eds.), Handbook of the philosophy of climate change (pp. 1–22). Springer.
Harris, M. (2021). The epistemic value of independent lies: False analogies and equivocations. Synthese, 199, 14577–97.
IPCC (2021). Climate change 2021: The physical science basis. In V. Masson-Delmotte, P. Zhai, A. Pirani, S.L. Connors, C. Péan, S. Berger, N. Caud, Y. Chen, L. Goldfarb, M.I. Gomis, M. Huang, K. Leitzell, E. Lonnoy, J.B.R. Matthews, T.K. Maycock, T. Waterfield, O. Yelekçi, R. Yu, & B. Zhou (Eds.), Sixth assessment report of the intergovernmental panel on climate change. Cambridge University Press.
IPCC (2013). Climate change 2013: The physical science basis. In T. F. Stocker, D. Qin, G.-K. Plattner, M. Tignor, S.K. Allen, J. Boschung, A. Nauels, Y. Xia, V. Bex, & P.M. Midgley (Eds.), Fifth assessment report of the intergovernmental panel on climate change. Cambridge University Press.
Jebeile, J., & Barberousse, A. (2021). Model spread and progress in climate modelling. European Journal for Philosophy of Science,11(66).
Joyce, J. M. (1999). The foundations of causal decision theory. Cambridge University Press.
Justus, J. (2012). The elusive basis of inferential robustness. Philosophy of Science, 79(5), 795–807.
Kass, R. E., & Rafterty, A. E. (1995). Bayes factors. Journal of the American Statistical Association, 90(430), 773–795.
Katzav, J., Thompson, E. L., Risbey, J., Stainforth, D. A., Bradley, S., & Frisch, M. (2021). On the appropriate and inappropriate uses of probability distributions in climate projections, and some alternatives. Climatic Change, 169(15), 1–20.
Knutti, R., Furrer, R., Tebaldi, C., Cermak, J., & Meehl, G. A. (2010). Challenges in combining projections from multiple climate models. Journal of Climate, 25(10), 2739–2758.
Lloyd, E. (2015a). Adaptationism and the logic of research questions. Biological Theory, 10, 343–362.
Lloyd, E. (2015b). Model robustness as a confirmatory virtue: The case of climate science. Studies in History and Philosophy of Science Part A, 49, 58–68.
Myrvold, W. (1996). Bayesianism and diverse evidence: A reply to Andrew Wayne. Philosophy of Science, 63(4), 661–665.
Myrvold, W. (2017). On the evidential import of unification. Philosophy of Science, 84(1), 92–114.
O’Loughlin, R. (2021). Robustness reasoning in climate model comparisons. Studies in History and Philosophy of Science Part A, 85, 34–43.
O’Loughlin, R. (2023). Diagnosing errors in climate model intercomparisons. European Journal for Philosophy of Science, 13(20), 1–29.
Parker, W. S. (2018). The significance of robust climate projections. In E. A. Lloyd, & E. Winsberg (Eds.), Climate modeling: Philosophical and conceptual issues (pp. 273–296). Palgrave Macmillan.
Parker, W. S. (2010). Whose probabilities? Predicting climate change with ensembles of models. Philosophy of Science, 77(5), 985–997.
Parker, W. S. (2011). When climate models agree: The significance of robust model predictions. Philosophy of Science, 78(4), 579–600.
Parker, W. S., & Risbey, J. S. (2015). False precision, surprise and improved uncertainty assessment. Philosophical Transactions of the Royal Society Part A, 373(3055), 20140453.
Perrin, J. (1916). Atoms. Trans. In D. L. Hammick (Ed.). D. Van Norstrand.
Schlosshauer, M., & Wheeler, G. (2011). Focused correlation, confirmation, and the jigsaw puzzle of variable evidence. Philosophy of Science, 78(3), 376–392.
Schupbach, J. (2018). Robustness analysis as explanatory reasoning. British Journal for the Philosophy of Science, 69(1), 275–300.
Schwingshackl, C., Davin, E. L., Hirschi, M., Sørland, S. L., Wartenburger, R., & Seneviratne, S. I. (2019). Regional climate model projections underestimate future warming due to missing plant physiological CO$_{2}$ response. Environmental Research Letters, 14(11), 1–11.
Sherwood, S. C., Webb, M. J., Annan, J. D., Armour, K. C., Forster, P. M., Hargreaves, J. C., Hegerl, G., Klein, S. A., Marvel, K. D., Rohling, E. J., Watanabe, M., Andrews, T., Braconnot, P., Bretherton, C. S., Foster, G. L., Hausfather, Z., von der Heydt, A. S., Knutti, R., Mauritsen, T., . . . Zelinka, M. D.(2020). An assessment of Earth’s climate sensitivity using multiple lines of evidence. Review of Geophysics, 58(4), e2019RG000678.
Smith, G. E., & Seth, R. (2020). Brownian motion and molecular reality: A study in theory-mediated measurement. Oxford University Press.
Stainforth, D. A., Downing, T. E., Washington, R., Lopez, A., & New, M. (2007). Issues in the interpretation of climate model ensembles to inform decisions. Philosophical Transactions of the Royal Society Series A, 365(1857), 2163–2177.
Stegenga, J., & Menon, T. (2017). Robustness and independent evidence. Philosophy of Science, 84(3), 414–435.
Wheeler, G. (2012). Explaining the limits of Olsson’s impossibility result. Southern Journal of Philosophy, 50(1), 136–150.
Wheeler, G., & Scheines, R. (2013). Coherence and confirmation through causation. Mind, 122(485), 135–170.
Winsberg, E. (2018). Philosophy and climate science. Cambridge University Press.
Winsberg, E. (2021). What does robustness teach us in climate science: A re-appraisal. Synthese, 198, 5099–5122.
Acknowledgements
My thanks to Wendy Parker, who helpfully provided thorough comments on earlier drafts of this paper on two separate occasions; Morgan Thomson; and a number of anonymous referees for comments on earlier versions of this paper.
Funding
Funding for this paper was provided in part by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Project 254954344/GRK2073 and in part by the National Science Foundation under Grant No. 2042366.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Dethier, C. Contrast classes and agreement in climate modeling. Euro Jnl Phil Sci 14, 14 (2024). https://doi.org/10.1007/s13194-024-00577-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13194-024-00577-6